Quick Answer
Cloud native cost optimization is the practice of controlling and reducing spend across containerized, serverless, and microservices-based architectures. Unlike traditional cloud cost management, it requires granular, real-time visibility into workloads where resources spin up and down in seconds. The goal is not just lower bills — it is better unit economics: knowing your cost per transaction, per customer, or per feature.
Cloud native adoption has reached 89% among surveyed organizations, according to the latest CNCF annual survey. Kubernetes is even more entrenched, with 93% of organizations using, piloting, or evaluating it. Meanwhile, global IT spending is on track to reach $6.15 trillion in 2026, with data center spending alone surpassing $650 billion. That is a lot of money for something most CFOs still cannot explain line by line.
Here is the uncomfortable part: industry research consistently places cloud waste at around 29% of total IaaS and PaaS spend, and for the first time in five years, that number is going up, not down. Cloud-native architectures, for all their operational advantages, can make that waste harder to find. Containers live for minutes. Lambda functions bill in milliseconds. Microservices scatter cost across hundreds of endpoints. The old playbook of monthly billing reviews and manual tagging does not cut it here.
The question that should drive every cloud-native investment is not “are we under budget?” It is “was it worth it?” Are the dollars going into containers, functions, and managed services producing proportional business value? Most organizations cannot answer that question today. This guide explains how to get there.
Below, we break down why cloud-native environments create unique cost challenges, what cloud infrastructure cost optimization strategies actually work, and how to build a cost optimization framework that keeps pace with the way modern engineering teams ship software.
What Is Cloud Native Cost Optimization?
Cloud native cost optimization is the discipline of managing, measuring, and reducing spend in environments built on containers, microservices, serverless functions, and managed cloud services. It goes beyond traditional cloud cost management by accounting for the dynamic, distributed nature of cloud-native workloads. Think of it as cloud computing cost optimization tuned for architectures where nothing sits still.
A useful distinction: traditional cloud cost management asks, “How much did we spend last month?” Cloud native cost optimization asks, “What did each transaction, each customer, and each feature cost us, and was the value worth it?”
That shift from aggregate to granular is what makes it both harder and more valuable. In a monolithic application running on a few EC2 instances, cost attribution is relatively simple. In a microservices architecture with 50 services, three cloud providers, and a mix of Kubernetes pods and Lambda functions, you need a fundamentally different approach to optimize cloud costs.

Research Report
FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.
Why Do Cloud Native Architectures Create Unique Cost Challenges?
If you have ever tried to tag a Kubernetes pod that existed for 90 seconds, you understand the problem intuitively. Cloud-native environments are designed for agility and resilience, not for cost transparency. That is a feature, not a bug, but it creates real financial blind spots.
- Short-lived resources resist traditional tracking. Containers and serverless functions spin up, do their work, and vanish. They do not sit still long enough for monthly billing reports to catch. The average number of containers per organization doubled from 1,140 to 2,341 between 2023 and 2024, according to the CNCF. That is a lot of transient resources generating cost data that traditional tools were never built to handle.
- Microservices distribute cost across dozens of boundaries. A single user request might touch an API gateway, three backend services, a message queue, a database, and a caching layer. Attributing the cost of that request to a specific product, team, or customer requires tracing the full execution path, not just looking at which AWS account the bill landed in.
- Serverless pricing is deceptively granular. AWS Lambda charges $0.20 per million requests plus $0.0000166667 per GB-second of compute. That sounds cheap until a misconfigured function runs 100 million times in a month — generating $20 in request charges alone before compute costs apply. Without anomaly detection, these costs compound before anyone notices.
- Auto-scaling hides waste in plain sight. Horizontal and vertical scaling are core to cloud-native design. But auto-scaling that responds to CPU spikes does not know if those spikes represent genuine demand or a memory leak. Scaling policies tuned for peak traffic can keep resources running (and billing) long after demand subsides.
- Shared resources make allocation ambiguous. A Kubernetes cluster might run workloads for five different teams. A managed database backs three services. Without a cost allocation strategy that operates at the workload level instead of the account level, you end up with averages that tell you nothing useful. Only 43% of organizations track cloud costs at the unit level, according to a 2025 Gartner analysis. The rest are flying blind and splitting costs evenly across teams regardless of actual consumption, which distorts the data for everyone.
How Does Cloud Native Cost Optimization Differ From Traditional Cloud Cost Management?
The following table summarizes the key differences. If your current approach lives mostly in the left column, you are managing cloud cost with a toolkit that was designed for a different architecture.
Dimension | Traditional cloud cost management | Cloud native cost optimization |
Resource lifecycle | Long-running VMs and reserved instances | Short-lived containers, pods, and functions |
Cost attribution | Account or tag-based allocation | Workload-level, per-service, per-request attribution |
Billing granularity | Hourly or monthly | Per-second, per-millisecond, per-invocation |
Optimization lever | Rightsizing and reservation purchases | Request optimization, concurrency tuning, architecture decisions |
Scaling model | Manual or scheduled scaling | Auto-scaling with event-driven triggers |
Visibility requirement | Monthly reports and dashboards | Real-time observability integrated with cost data |
Key metric | Total spend and budget variance | Unit economics: cost per customer, transaction, or feature |
FinOps maturity signal | “We know what we spent” | “We know what each dollar of spend produced” |
The table is not a knock on traditional approaches. If your infrastructure is mostly long-running VMs, tag-based allocation works fine. The problem is that 52% of organizations now use containers for most or all of their applications. The architecture has changed. The cloud infrastructure optimization approach needs to change with it.
What Are The Biggest Cost Drivers In Cloud Native Environments?
Not all cloud-native costs are created equal. Knowing where the money actually goes helps you prioritize optimization efforts instead of chasing small savings while the big costs go unchecked.
1. Container orchestration overhead
Running Kubernetes is not free, even when your workloads are small. Container cost optimization begins with understanding the baseline: the control plane, node pools, networking (particularly cross-AZ traffic), and persistent storage all carry costs that exist independently of your application workloads.
Understanding the difference between ECS and EKS pricing models, for example, matters more than most teams realize. EKS charges $0.10 per hour for the control plane alone, while ECS on Fargate bills purely based on vCPU and memory consumed.
Kubernetes cost optimization is a deep topic in its own right, but the biggest wins typically come from right-sizing pod requests and limits. Most teams set these once during deployment, copy-paste from a Stack Overflow answer, and never revisit them. Six months later, a pod requesting 4 GB of memory is happily consuming 600 MB while the cluster provisions nodes to feed its appetite.
2. Serverless function sprawl
Serverless architectures eliminate server management, but they introduce a different cost risk: function sprawl. Serverless cost optimization starts with knowing what you have. When spinning up a new Lambda function takes 30 seconds, teams create them liberally. Over time, you end up with hundreds of functions, some triggered millions of times per month, others orphaned but still attached to event sources that fire occasionally.
One quick win: Graviton-based (ARM) Lambda functions cost roughly 20% less per GB-second than x86, and AWS reports that most workloads need zero code changes to switch. Yet many teams still default to x86 because that is what the template said when they first set things up.
3. Data transfer and networking
The silent assassin of cloud-native budgets. Every service-to-service call that crosses an availability zone incurs data transfer charges. In a microservices architecture with dozens of cross-service calls per request, those charges add up quickly.
API gateway costs layer on top of that. Nobody ever gets promoted for optimizing data transfer, but plenty of people have had awkward conversations with finance because of it.
4. Managed service consumption
Managed databases (RDS vs. Aurora is a common decision point), caching layers, message queues, and AI API services all bill based on usage patterns that scale with your application. The convenience of managed services is real, but the cost can surprise you when usage grows beyond the comfortable free-tier numbers you were looking at during prototyping.
Storage costs tell a similar story. S3 pricing looks trivial at small scale, but container logs, application traces, and backup snapshots accumulate quickly in a cloud-native environment where every microservice produces its own telemetry stream. Teams that do not set lifecycle policies on log buckets discover this the hard way, usually around month six of a new deployment.
5. Observability and monitoring overhead
This is the cost driver nobody budgeted for. Cloud-native environments produce orders of magnitude more telemetry than monoliths. Every container emits metrics, every function logs its execution, and distributed tracing generates spans across every service boundary. Application monitoring is essential for operating microservices, but the monitoring bill itself can become a top-five line item if you are not selective about what you collect and how long you retain it.
The tools required to find waste can themselves become a significant source of waste if data retention policies and collection scope are not managed actively.
Understanding these cost drivers is the “you are here” marker on the map. The next question is what to do about it. Here are seven strategies that are working for cloud-native teams in 2026, ranked not by cleverness but by how much money they actually save.
What Are The Best Strategies To Optimize Cloud Native Costs In 2026?
Most cloud-native cost savings come from several areas. Some are configuration changes you can ship this week. Others are cultural shifts that take quarters. All of them work better in combination, because visibility without action is just an expensive dashboard.
Before applying these strategies, confirm you have these fundamentals in place:
Prerequisite | Why it matters |
Container orchestration observability | Kubernetes metrics (pod CPU/memory utilization, node allocations) must be collectible. If you can’t measure pod-level resource usage, you can’t right-size. |
Cloud billing data at line-item granularity | AWS CUR, Azure Cost Management Export, or GCP Billing Export — not monthly summary invoices. Cloud-native optimization requires per-resource, per-second cost data. |
Service topology map | Know which services call which other services, which teams own which namespaces, and which customers drive traffic through which endpoints. Without this, cost allocation is guesswork. |
A “cost per X” target metric | Decide what your unit economics denominator is — cost per customer, cost per transaction, cost per feature — before optimizing. Otherwise you’re cutting costs with no business context. |
1. Implement cost allocation at the workload level
Tags are necessary but insufficient. In a Kubernetes environment, you need namespace-level and label-level cost attribution that can handle short-lived workloads. The goal is connecting every dollar of spend to a team, a service, or a business outcome. Full cost allocation is the foundation; without it, everything else is guesswork.
Start by mapping your service topology. Which services call which other services? Which teams own which namespaces? Which customers drive the most traffic through which endpoints? This mapping is the scaffolding that makes all downstream optimization possible. It also surfaces a common problem: shared infrastructure costs that nobody owns and everybody ignores.
2. Right-size pod requests and limits continuously
Overprovisioned pods are the cloud-native equivalent of idle EC2 instances, except they are harder to spot because they are technically “doing something.” (The something is mostly sitting there, but they look busy on a dashboard.) Audit the gap between requested and actual CPU and memory usage.
A pod requesting four vCPUs but typically consuming one is wasting 75% of its allocated capacity. Multiply that across a cluster, and the savings from right-sizing often reach double digits without touching application code.
3. Adopt unit economics as your primary cost metric
Stop tracking total spend as your headline number. Start tracking cost per customer, cost per transaction, or cost per API call. If total spend goes up 40% but your per-customer cost drops 15%, you are winning.
If total spend is flat but per-unit costs are climbing, you have a problem that aggregate dashboards will not show you. CloudZero’s approach to unit economics gives engineering and finance teams a shared language for making these tradeoffs.
4. Optimize serverless configurations, not just code
Memory allocation in Lambda is the most common tuning mistake. A function with 512 MB of memory might take one second to complete; the same function at 1,024 MB might finish in 400 milliseconds. Because Lambda bills per GB-second, the faster, larger-memory configuration can actually cost less. Use AWS Lambda Power Tuning to find the optimal memory setting for each function.
Beyond memory, batch your SQS-triggered invocations. Processing 10 messages per invocation instead of one cuts your request charges by 10x. Small configuration changes like this are the low-hanging fruit of cloud infrastructure cost optimization.
5. Control data transfer costs proactively
Architect for data locality. Place communicating services in the same availability zone where possible. Use VPC endpoints instead of NAT gateways for AWS service traffic. Cache aggressively at the edge. For multi-cloud environments, be especially aware of egress charges, which vary widely across providers.
A practical example: a microservices application with 20 inter-service calls per user request, spread across three availability zones, can accumulate data transfer charges that exceed the compute cost of the services themselves. Consolidating high-traffic service pairs into the same AZ is one of the highest-ROI optimizations available, and it costs zero engineering effort beyond a configuration change.
6. Implement real-time anomaly detection
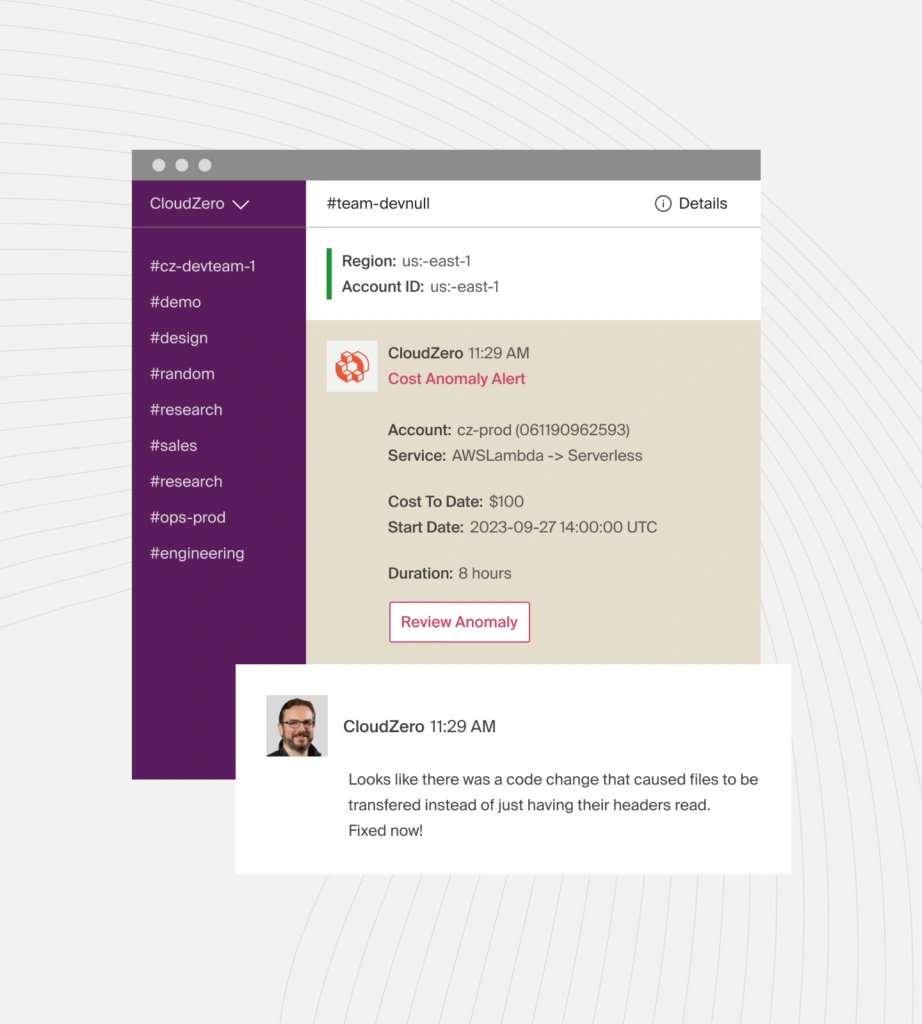
In cloud-native environments, cost anomalies compound in hours, not weeks. A misconfigured auto-scaling policy or an infinite loop in a serverless function can generate thousands of dollars in charges before a monthly report catches it. Continuous cost monitoring with automated alerts is not optional in environments where resources scale dynamically.
The key is setting alerts at the service level, not just the account level. An account-level budget alert that fires when total spend crosses $50,000 is like a smoke detector for the whole building: it tells you something is on fire but not which floor. Service-level anomaly detection catches problems at the source and tells the right team to investigate.
7. Make cost part of the engineering workflow
The State of FinOps 2026 report found that workload optimization and waste reduction remain the top priority for practitioners, across 1,192 respondents managing over $83 billion in annual cloud spend. But getting engineers to act on cost recommendations remains the top challenge, according to FinOps Foundation community data. The gap between knowing about waste and fixing it is an engineering culture problem, not a tooling problem.
Cost data needs to show up where engineers already work: in pull request reviews, deployment pipelines, and sprint retrospectives. Not in a quarterly finance deck that gets skimmed during the meeting and forgotten by the elevator.
This is also where the FinOps maturity conversation gets real. As of the 2025 State of FinOps survey, only 14.2% of organizations had reached “Run” maturity, the advanced stage where cost optimization is embedded in daily engineering decisions. The 2026 report paints an even sharper picture: mature practitioners report diminishing returns on traditional optimization, saying they have “hit the big rocks” and now face smaller, harder-to-capture savings.
CloudZero’s 2026 research with Benchmarkit tells the same story from a different angle: FinOps adoption roughly doubled in a single year, yet cloud efficiency scores dropped. More organizations are “doing FinOps” on paper, but fewer are getting measurable results from it. The report calls this a Critical Recalibration moment, one where the gap between having a FinOps practice and having an effective one is wider than ever.
For cloud-native teams, closing that gap starts with giving engineers visibility into the cost impact of their architectural choices, not just their instance selections.
Cloud Native Cost Optimization Cheat Sheet
Strategy | Primary target | Effort | Typical impact |
Workload-level cost allocation | Shared infrastructure | Medium (mapping exercise) | Foundation — enables all other optimization |
Right-size pod requests/limits | Kubernetes clusters | Low (audit + config change) | 15–30% compute reduction per cluster |
Adopt unit economics metrics | Entire org | Medium (tooling + culture) | Shifts conversation from “reduce spend” to “improve efficiency” |
Optimize serverless configs | Lambda / Cloud Functions | Low (Power Tuning tool) | 20–40% per-function cost reduction |
Control data transfer costs | Cross-AZ/cross-region traffic | Low (architecture review) | Can exceed compute savings in microservices architectures |
Real-time anomaly detection | All dynamic workloads | Medium (alerting setup) | Prevents runaway costs; ROI is in what you avoid |
Cost in engineering workflows | Engineering culture | High (process change) | Highest long-term impact; lowest short-term ROI |
How Do You Measure Cloud Native Cost Efficiency?
Traditional cost metrics like total spend, budget variance, and savings rate still matter. But in a cloud-native environment, they do not tell the full story. They tell you what you spent. They do not tell you what you got for it.
This is the core of what CloudZero calls the “cost per anything” approach: the ability to measure infrastructure spend against any business dimension that matters to your organization. Not just cost per account or cost per service, but cost per customer, cost per transaction, cost per feature, cost per deployment. The metric you choose depends on your business model. The principle is the same: tie every dollar to a business outcome, then decide if it was worth it.
Here are the unit economics metrics that matter most in cloud-native environments.
- Cost per customer. If your platform serves 10,000 customers and your total cloud-native infrastructure costs $200,000 per month, your average cost per customer is $20. But averages lie. Ten customers might drive 60% of your compute costs. One customer with a particularly creative API integration might be single-handedly funding your auto-scaling bill. Knowing that changes how you price, how you architect, and how you prioritize optimization.
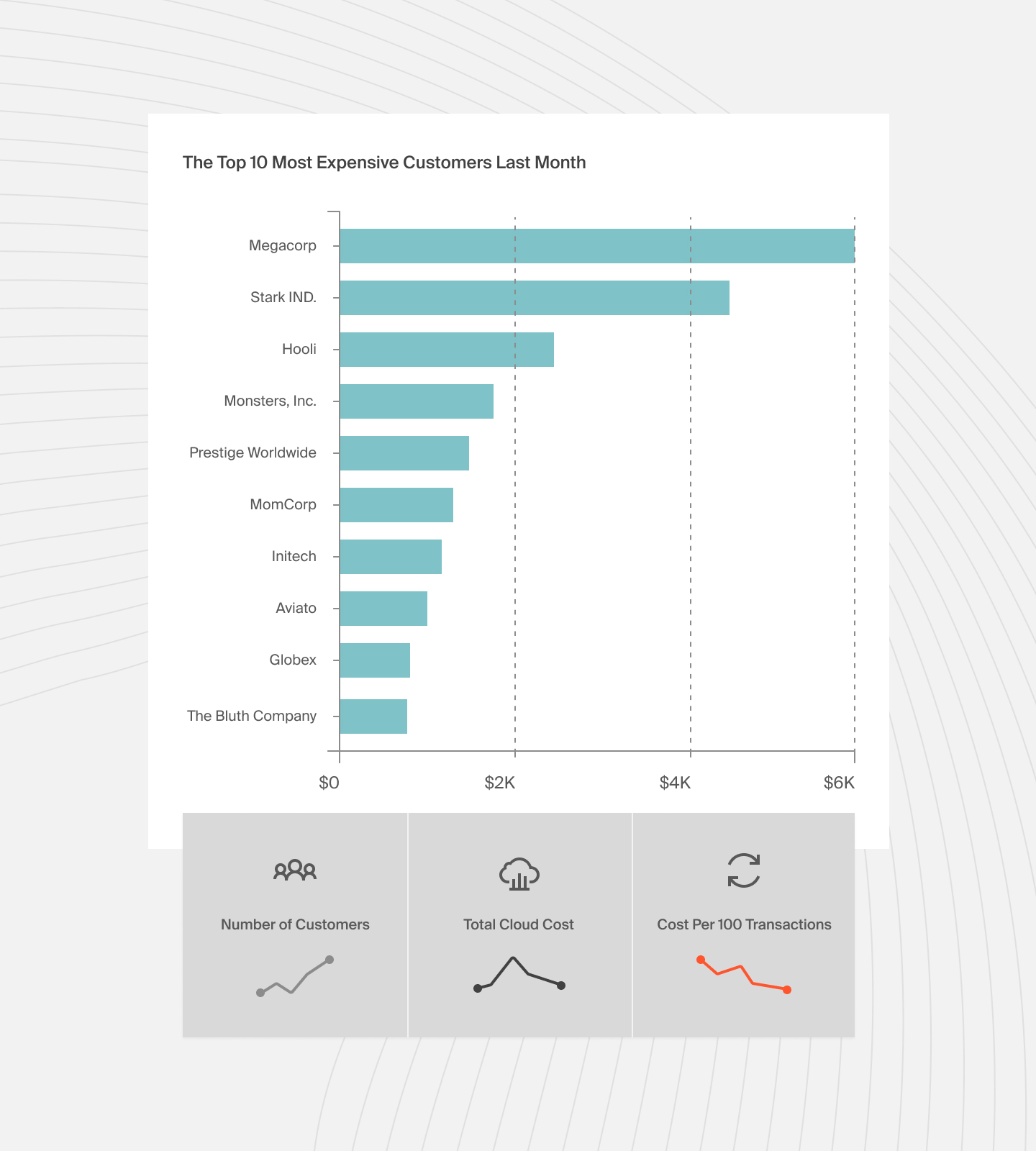
- Cost per transaction. For API-driven businesses, tracking the cost of each API call or each processed order gives you a metric that engineering, finance, and product teams can all act on. When cost per transaction goes up, it is a signal to investigate. When it goes down while transaction volume grows, you know your architecture is scaling efficiently.
- Cost per feature or service. In a microservices architecture, you can measure the cost of running each individual service. This makes it possible to ask pointed questions: is the recommendation engine worth its $12,000/month infrastructure cost? Is the real-time notification service delivering enough value to justify its compute and messaging charges?
- Cloud Efficiency Rate. This metric compares your optimized spend to what you would have spent at on-demand pricing without any optimization. It captures the cumulative impact of reserved instances, savings plans, spot usage, right-sizing, and architectural improvements. A rate above 70% indicates strong cost discipline; below 50% suggests meaningful optimization opportunities.
The common thread: all of these metrics require cloud infrastructure optimization at a level of granularity that native cloud provider tools do not provide out of the box. You need to correlate billing data with business metadata to get from “we spent $200K on AWS this month” to “our cost per customer dropped 8% while we onboarded 500 new accounts.”
How Does CloudZero Approach Cloud Native Cost Optimization?
The question at the center of every cloud investment decision is deceptively simple: was it worth it?
Not “did we stay under budget?” That is a financial question with a binary answer. The real question is operational: did the dollars we spent produce proportional business value? Did our per-customer economics improve as we scaled? Did the new microservice we deployed last quarter deliver enough revenue impact to justify its infrastructure footprint?
Answering those questions in a cloud-native environment requires a different kind of cost platform. Traditional cost tools were built for static infrastructure. They assume resources have stable identifiers, live for hours or days, and can be tagged at creation. Cloud-native workloads violate every one of those assumptions.
CloudZero approaches this differently by connecting cloud cost data to business dimensions without relying on tags as the primary allocation mechanism. This means you can see spend per customer, per feature, per microservice, and per deployment, even across Kubernetes environments where pods are created and destroyed constantly.
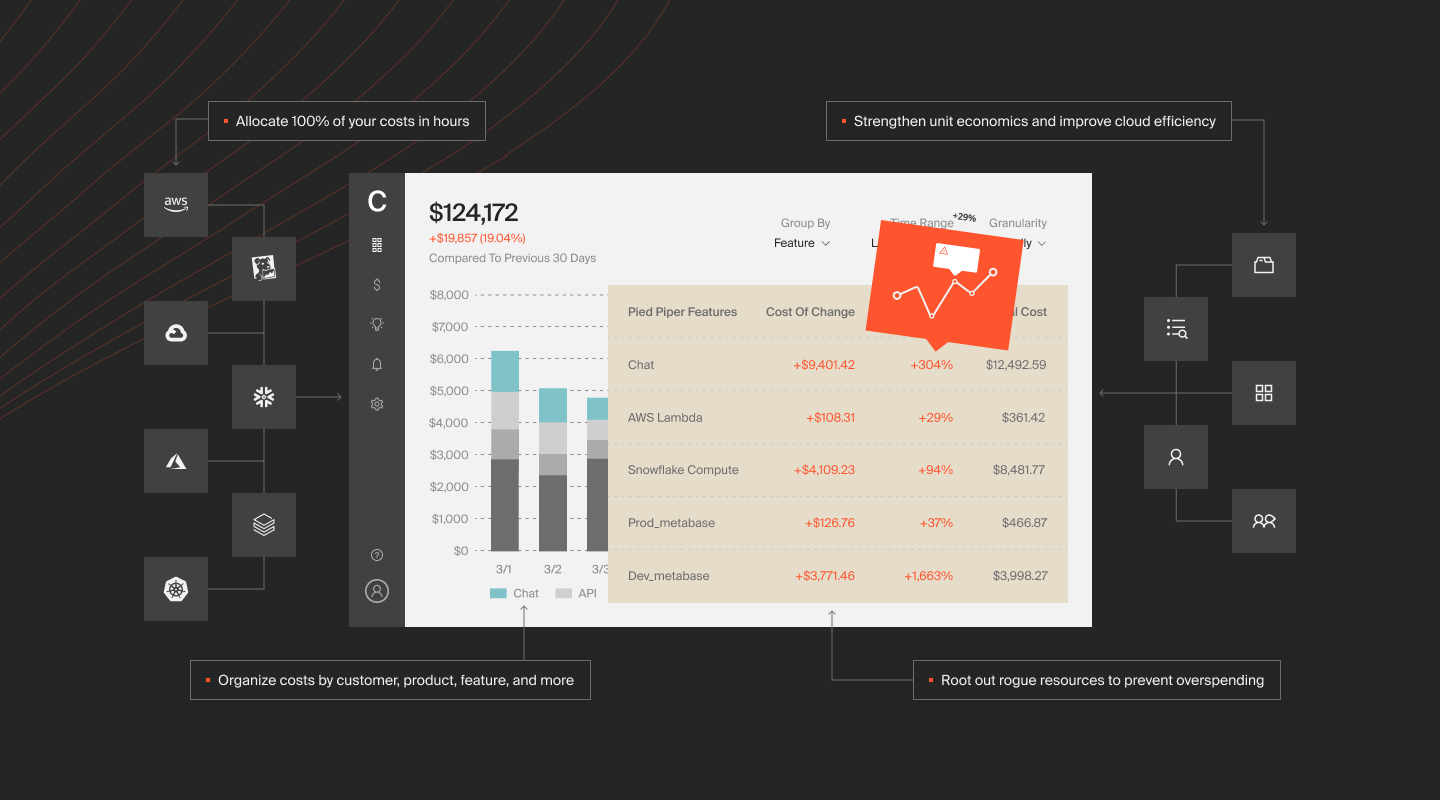
The platform’s anomaly detection monitors cost streams continuously and flags deviations before they become budget problems. Its unit economics capabilities let engineering and finance teams evaluate spend in business terms, not just infrastructure terms.
Its Cost Explorer and CUR-level integration provides the billing granularity that cloud-native workloads demand.
For running cloud-native workloads across AWS, Azure, or GCP, the combination of tag-free cost allocation, continuous visibility, and business-level cost metrics fills the gap that native cloud management tools leave open. It turns the question from “what did we spend?” into “was it worth it?” That is the question that actually drives better decisions.
With CloudZero, the numbers speak for themselves…
CloudZero customers average 22% savings in year one. But the standout results go well beyond averages:
- Upstart, the AI lending platform, targeted $10 million in cloud savings and ended up saving $20 million without slowing product innovation.
- PicPay, one of Brazil’s largest fintech platforms, saved $18.6 million by gaining visibility into costs they could not previously attribute.
- Symphony Talent cut AWS costs by 48% using CloudZero’s engineering-led optimization approach.
- Drift saved $2.4 million in its first year as a CloudZero customer by segmenting costs by service and responding to anomalies in real time.
They join billion dollar companies such as Duolingo, Toyota, Skyscanner, Coinbase, and Wise that use CloudZero to turn cloud spend into a strategic advantage.
You can too.  to see exactly where your cloud-native spend is going, what it is producing, and where the biggest optimization opportunities are. Or take a self-guided product tour to see CloudZero in action.
to see exactly where your cloud-native spend is going, what it is producing, and where the biggest optimization opportunities are. Or take a self-guided product tour to see CloudZero in action.
Frequently Asked Questions About Cloud Native Cost Optimization


FinOps In The AI Era: A Critical Recalibration
What 475 executives told us about AI and cloud efficiency.